
Acceptable Hyperparameters and How to Find Them
A tool for the innumerate FLOPhead

Not the tool we deserve, but the tool we need
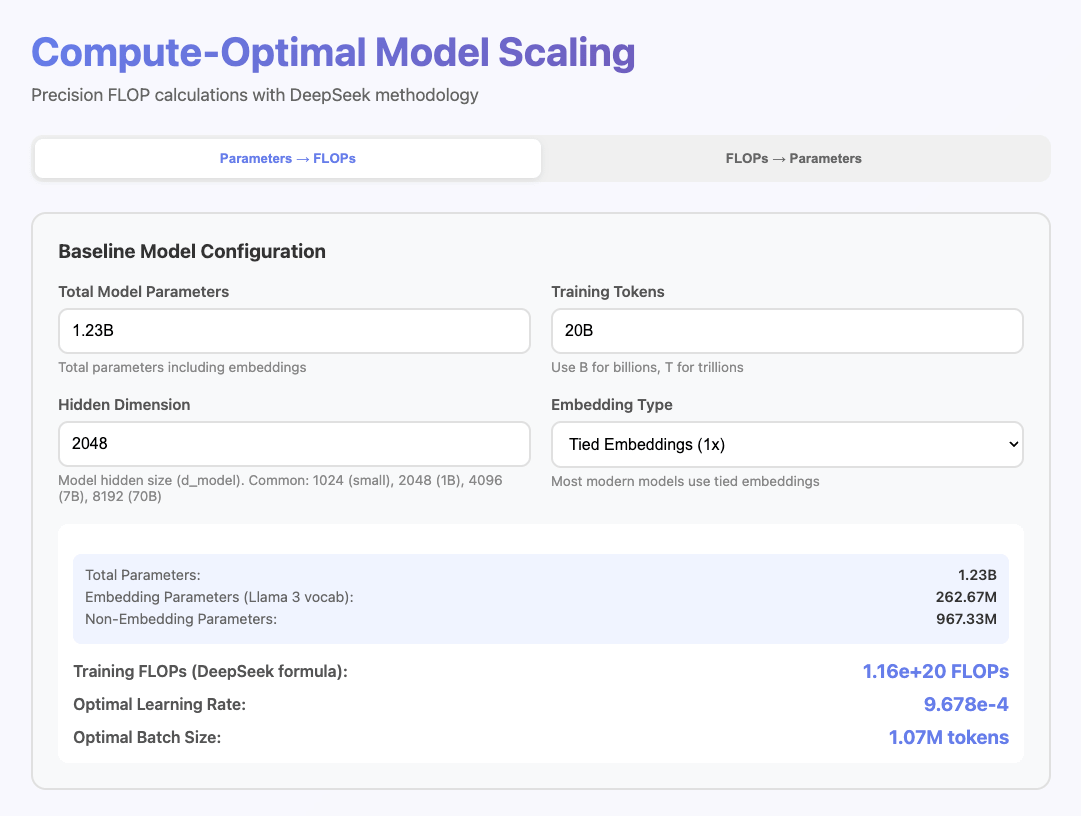
Selecting hyperparameters for pretraining LLMs is hard. Often during research it’s the last thing you want to do, and feels like a roadblock between you and the question you are actually trying to answer. Batch Size, Learning Rate, Grad Accum Steps, Sequence Length, How many nodes or gpus you are using. It’s all a pain. So I made a little tool for myself to find “very reasonable” values quickly. I thought more people might like it so I’m going to share it and explain how it works. Check it out!
Context
I’ve had the fortune of working with lots of talented people in my career. The most fascinating and mysterious of these people were the hardcore FLOPheads. They had all sorts of constants and numbers memorized they could produce from the top of their head. Peak TFLOPs of different hardware, the largest model size that would fit on a single GPU or node for a given sequence length. They were also fascinated with making projections of pretraining in spreadsheets. You would ask them what config you should use for a given run and they’d pull out this sheet that was hundreds of rows long calculation of dozens of architectures then start waxing poetically about the trade offs of each one before asking you to take a stab at adding a row yourself. One particular engineer would often look at my attempts and just send me a slack message that said “skill issue” (I frequently broke the spreadsheets). If you are like me this is anarchy. Obviously this is incredibly useful, but the mental load was overwhelming. Well its 2025 and we are in the age of vibecoding. We don’t have to live like this. All of us can be FLOPheads. Even us math challenged folks.
How does it work
Its based on the empirical scaling laws from the DeepSeek V1 tech report
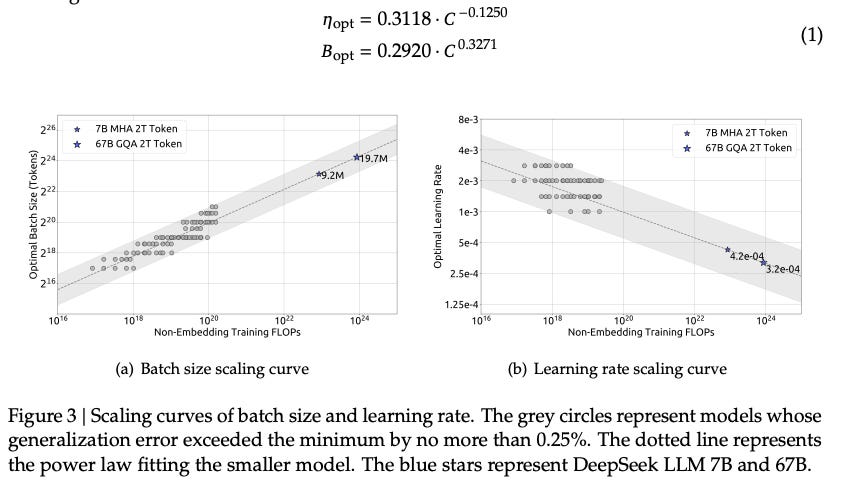
Basically they found that they could fit batch size and learning rate with respect to compute budget after sweeping values at smaller FLOP values and predict out near optimal values multiple orders of magnitude larger. This calculator then is simply taking your model information (total parameters, hidden dimension size) approximating its Non-Embedding Parameters, Calculating the Training FLOPs based on the desired Training Tokens and calculating the optimal Batch Size and Learning rate for the given compute budget.
Oh and very importantly you need to use AdamW with
beta1 = 0.9, beta2 = 0.95, weight_decay = 0.1Other Bells and Whistles
But wait, theres more! It also can help with batch sizes, alternative model sizes, and finding compute optimal models for a given FLOP budget.
Highly divisible batch sizes
One of the annoying things about this formula, and configuring training in general is its often better to calculate batch size in terms of tokens per step, but that leaves you with lots of additional math and tinkering you would normally need to do yourself. Translating this into an actual global batch size for your desired sequence length being a big one.

Here is where it becomes really handy. Not just for correctness, but as a FLOPheads best friend. It does some quick brute force calculations to translation to take optimal tokens per step and find highly divisible sequence counts at different context lengths informing you of how well they approximate the optimal value. Why is this cool? Well if you are an intern or grad student with low priority access to a cluster and want to soak up every available FLOP at your disposal you now have a lot more options than just powers of 2. You see 3, 5, 6 nodes available? Go ahead and grab them. you deserve it. You don’t have equity anyways right?
It’s also helpful if you are doing a big serious hero run. GPUs on large clusters have pretty high failure rates. In fact you can even approximate how often a training run will be interrupted by gpu failures (thats probably a whole other blog). Suffice it to say if you lose a node during an expensive run its very desirable to be able to resume on *almost* as many nodes as before instead of having to cut your training job in half while you wait on your provider to swap out or reboot the bad node.
There are additional FLOP head friendly benefits to doing this as well. Anyone who has struggled with and FSDP config and activation checkpointing has experienced the pain where they have spare memory, but they cannot increase their local batch size to a valid number to divide their global batch size without OOMing, and if you increase it you now need activation checkpointing but now it’s slower than the smaller local batch size without checkpointing.

Imagine the case where you have room in memory for a Micro-batch size of 4 with some to spare, but Micro-batch size of 8 absolutely will not work. If you use sequences of power of 2 you are out of luck. Go reach for tensor parallelism and cry. If you had done a bit more planning though and used a highly divisible number instead, well look at that 6 works and now your gpus are going brrrr.
Alternate Model Shapes
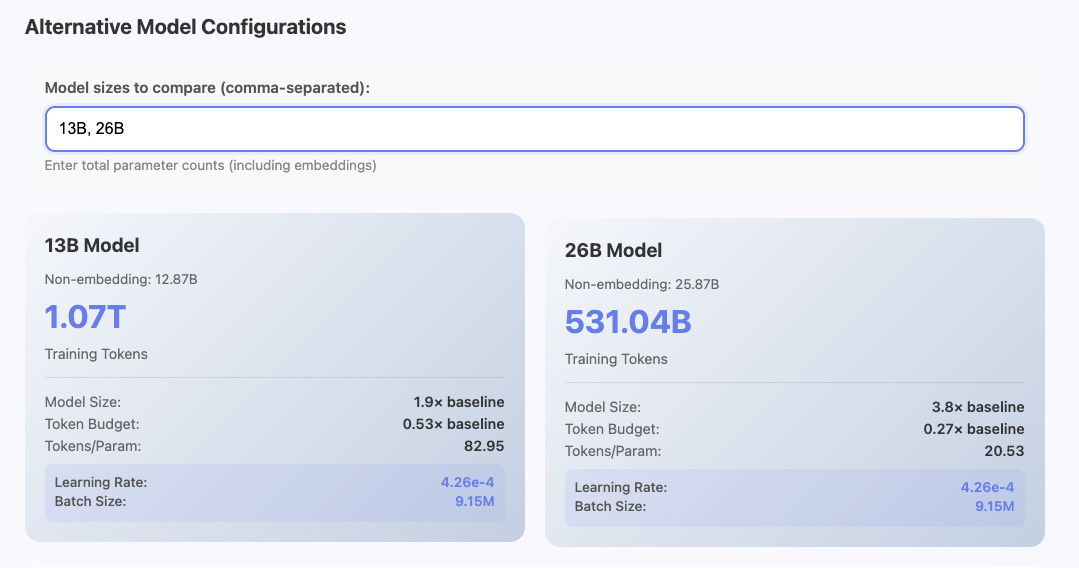
FLOPs → Parameters
Another thing that can happen in pre-training research is maybe you know a FLOP budget for an experiment and you want to turn that into a model config or a tokens per parameter ratio. A good example of this is when you want to ensure you pass the emergence point on a given benchmark of capability you are studying. While changes in data is the best way to shift emergence points of compute, its generally pretty predictable where these points will be using historical run data. Maybe you know you want to be just about 1e22 FLOPs to make sure you get solid signal on GSM8K with generic pre-training data. You also want the highest signal per FLOP you can. The LR and batch size are set with respect to compute, so no need to change this.
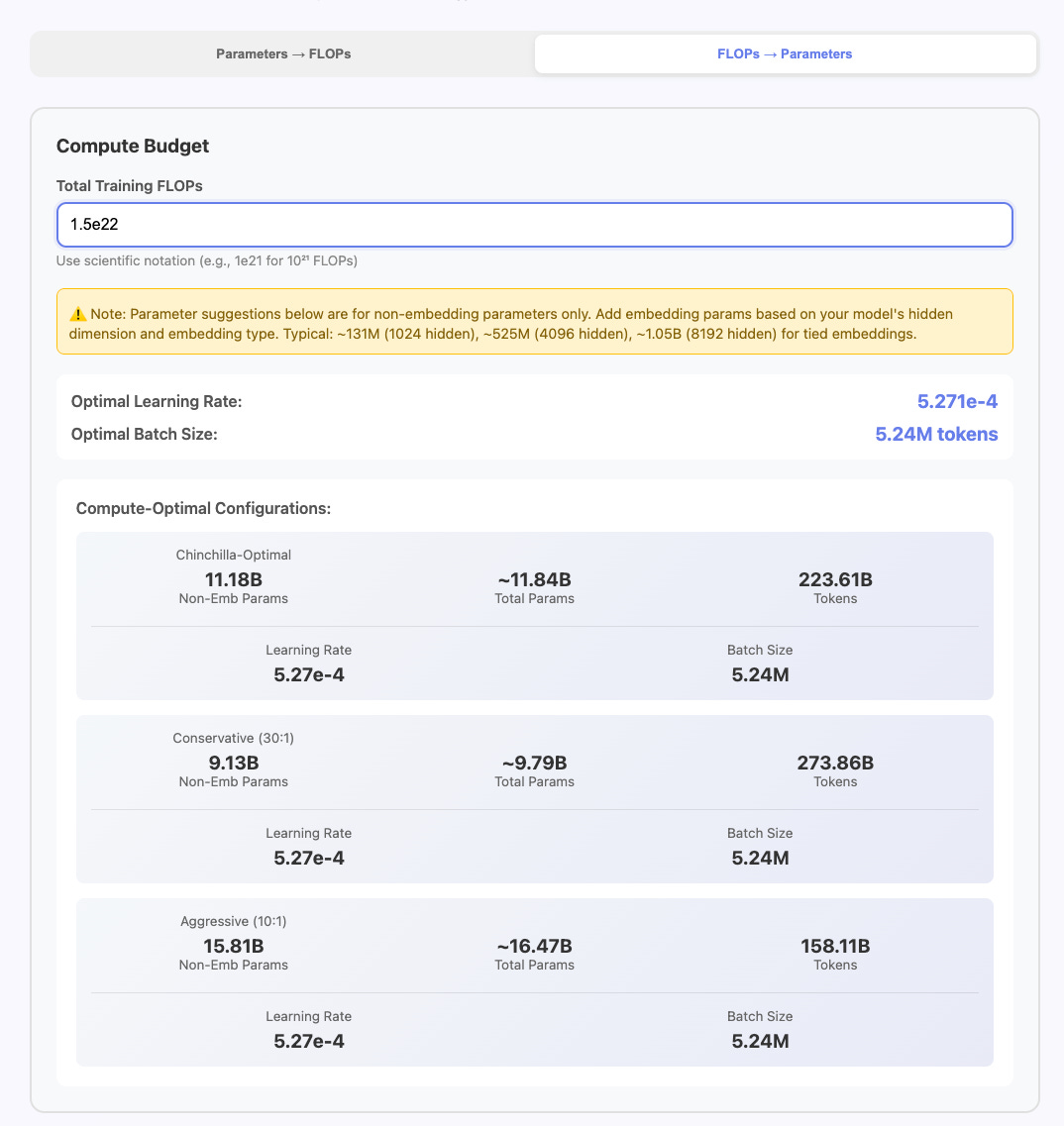
If you click the tab to go to FLOPs → Parameters you can enter a desired FLOP budget and get out different token’s to parameter ratios. Chinchilla-Optimal is still a pretty reasonable starting point for most datasets / arch if you don’t feel like doing your own scaling law experiments
How can it be improved
There are a bunch of assumptions baked in to DeepSeek’s coefficients going into this calculator as you might have guessed. The first is that it is for dense models. Well specifically their dense model. Its very similar to Llama 3 but deeper for the same parameters. If you are using Llama 3 or Qwen2/3 as the base for your model this is probably close enough.
It does however assume a given dataset. DeepSeek’s dataset to be exact. While I have found personally that these constants tend to work pretty well on many different datasets, if you wanted to squeeze the maximum performance out of this you could recalculate the constants that DeepSeek uses yourself.
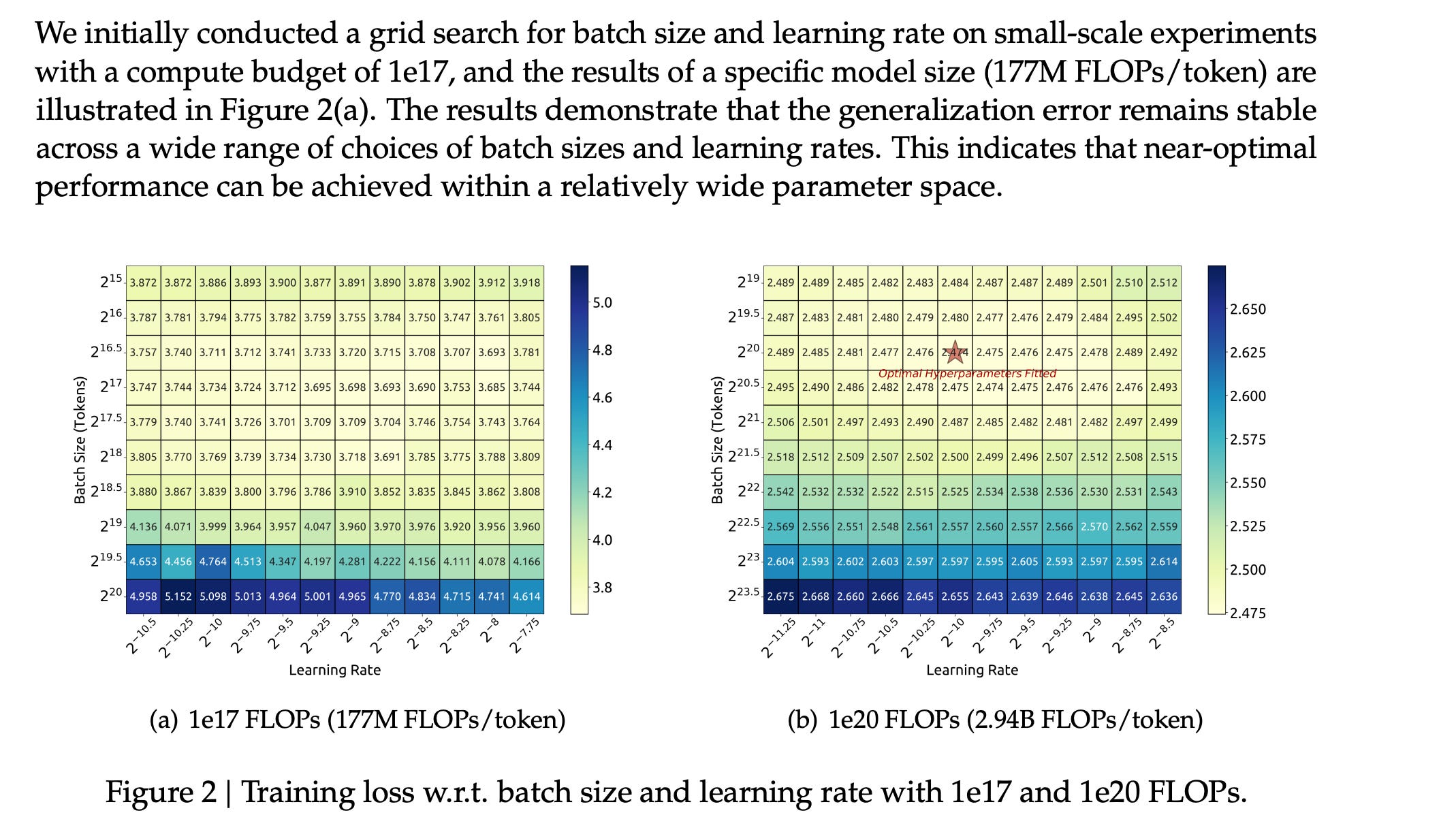
If you have made some wild architecture changes, or you have a new cracked dataset just repeat the process.

Sweep your hyperparamters from 1e17-2e19 flops. Exclude values that exceed the minimum loss by 0.25%, then fit your batch size and learning rate. Very simple.
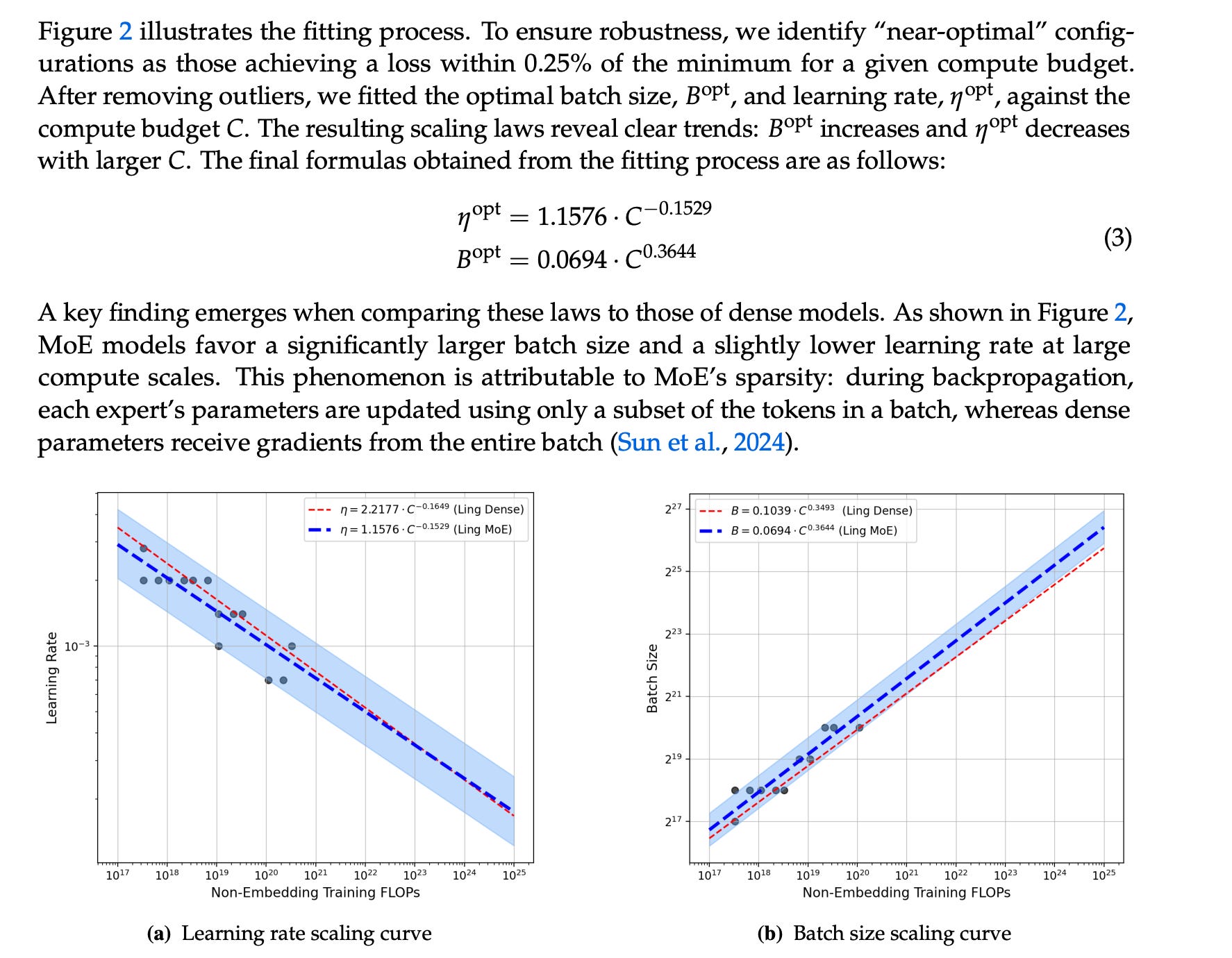
Not training a Dense model? Well what do you know it also works for MoEs with some constraints.
Conclusion
So thats it. Short and sweet. You can use this calculator to find your hparams for training runs. After you do so you can choose something more FLOPhead friendly for tuning your MFU. If you have a config you are currently using and want to find something that is closer to compute optimal it can help with that. If you know your FLOP budget and want to choose a model size it can help with that too. May the FLOPs be with you.
You might be thinking to yourself “well this isn’t so complicated, what is it just a single html page?” and you would be right! I’ve been using it personally for work and its been very helpful. I’ve been too lazy at this moment to make a bunch of changes that might make it more useful, but I have put it on github. Feel free to fork it, make PRs, etc. If enough people find it helpful I might keep working on it.
This is a great read! Perfect length too. Thanks for sharing!
This is amazing! Love the practicality!